自炊のイロハ
書籍を裁断してスキャンすることを自炊と呼ぶらしい。なんのアナロジーなのかあるいは語呂合わせなのか解らないが、とにかくそう呼ぶらしいのだ。だったらKindleとかでダウンロードするのは外食なんだろうか。
iPadの発売以降、裁断から取り込みのノウハウ紹介やレポート記事を時々見かけることが多くなった。どれも参考になる点が多い。便乗するわけではないが(あるんだけど)自分でも幾つか気づいた点を交えつつ手順を紹介してみたいと思う。
今回のターゲットはこの技術書。主に仕事で使うのだが、会社の金で買うことは少ない。会社では部門の予算で買うことに関して嫌な顔をされることはなく、むしろ積極的に買えと言っているのだが、俺は書き込みをしたりページを折ったりしながら乱暴に扱うことが多く、また新しい基礎知識は業務時間外に習得するようにしている*1ので、自分で買っている。今回のように本をばらばらに解体するような場合は上記の理由がなくても自分で買った方が良いだろう。


- 作者: 羽田野太巳
- 出版社/メーカー: 秀和システム
- 発売日: 2010/02/26
- メディア: 単行本
- 購入: 12人 クリック: 451回
- この商品を含むブログ (25件) を見る
この本は600ページ近くあるので裁断機に入らない。このような厚い本は分割してから裁断する。今回は3つに分割することにした。分割の際は、まず背表紙に折り目をつけてやる。上から見て、紙の固まりの間で分割すると切りやすい

背表紙は普通のカッター*2で簡単に切ることができる。俺はこうやって背開き(背表紙側から刃を当てる)にするが、腹開きの方がやりやすいという人もいるようだ。

中の紙面を切らないように注意しつつ三分割。こんな感じになる。

ひとつづつ背中の部分を、裁断機でざっくんしてやる。コツは「大胆に切る」ことなのだが、どうしても変なところで「切りすぎないようにしよう」「余白のバランスも考慮しておこう」といった職人意識(たぶん違う)が邪魔をして短めに切ってしまう。

なお、裁断機に関しては「プラス PK-513L」をお勧めする。他は試していないので比較はできないのだが、とにかく使いやすくてよく切れる。欠点は値段だけだ。
切り終えた本がこちら。ぱっと見は普通の本だが…

実はバラバラ。ミステリでは「生きているかのように座っている人に近づいてみたら死んでいた」といったシーンがおなじみだが、上の写真の状態で放置された本を知らずに誰かが手に取れば同じような気分を楽しめるかもしれない。

地味なので写真は省略するが、ここで裁断した本から、カバーの下の固い表紙とその次の無地の色紙を取り除いた。全部残したい人もいるだろうし、逆に不要なページは徹底的に取り除きたいという人もいるだろう。この辺はお好みで。
ここでスキャン開始と行きたいところだが、その前にカバーの解体もやっておく。カバーは不要という人もいるかもしれないが、本はタイトルより表紙で覚えていることも多々あるので、スキャンしておいた方が役に立つような気がするのだ。
カバーの解体には、ハンズの文房具売り場で買ったスライドカッターを使っている。
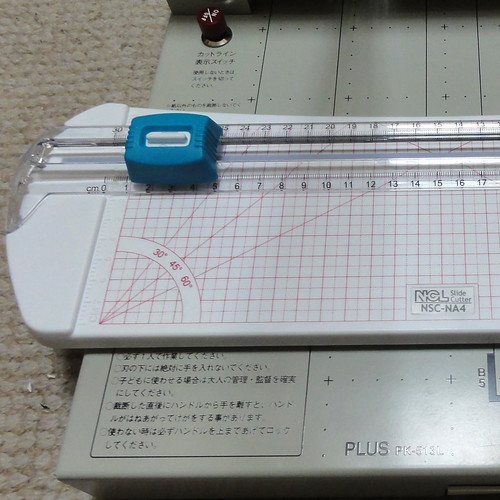
このようにセットして、左下の青い部分を滑らすとまっすぐに切ることができる。あまり正確さを求めずに挑んだ方が良いだろう。まず、折り返しの部分を980円で買ったカッターで刈った。

そしてこれが5枚におろしたところ。980円で買ったカッターで刈った俺が勝ったのだ。5枚におろしたカバーは全部取り込むもよし、必要な部分だけ取り込むもよし、お好みで。今回は折り返しの部分に有用な情報がないので、表紙と裏表紙のみをスキャンすることにした。背表紙はスキャンしたことがないが、細長いので、もしやるとしたらコツが必要になるだろう。

エイリアンさん監督の下、ScanSnapで取り込んでいるところ。特に理由が無い限り、取り込みはPDF形式にしている。

取り込むときに最も注意するべき点は「糊」だ。糊が残っているとページ同士がくっついてしまい、一度に2枚スキャンされたり、ジャムってしまうのだ。2枚スキャンが起きた場合はScanSnapがアラートを出してスキャンを停止するので、紙をセットし直してスキャンを再開すれば良いだけなのだが、ジャムの場合は紙が折れ曲がったり、破けたりしてしまうので、たちが悪い。
深めに裁断すればするほど糊が残ることが少なくなるのだが、先にも述べたようについ浅めに裁断してしまい、糊が残っている事がある。そのような場合は「もう一度裁断する」あるいは「スキャナにセットする際にチェックする」くらいしかトラブルを避ける方法はない。チェックの際は一枚一枚背中側からめくって、分離を確認するのがベストだが、面倒な場合は数十枚ずつ手にとって切断面を指でなぞれば糊が残っている部分をある程度見つけることができるが、この方法で見つからないことももちろんある。また、本の構成上何ページかおきに折り重なりの薄いところがあり、そこは糊が奥まで浸透しやすいものと思われる。もしかしたら、ページ番号からある程度推測できるかもしれないので、今後の研究課題としたい。
今回は、慎重にチェックしたつもりだが3カ所トラブルがあった。重なり検出が2回とジャムが1回だ。PDF化したあとで、トラブルのあったページをチェックできるようにしておくと後で楽だ。

これまた、地味なので写真は省略するが、PDF化の後でScanSnapについてきたアドビ・アクロバットを使ってPDFファイルをもっと使えるようにする場合がある。今回は次の2つの作業を行った。
【作業1:OCR】OCR(自動文字認識)で認識された文字データはPDFファイルに埋め込まれ、アドビ・リーダー等のアプリケーションを使えば検索が可能になる。雑誌の場合は文字が小さかったり、デザイン上文字認識が難しい場合もあって、取り込んだらそのままだが、技術書籍の場合は検索可能なようにOCRをかけておく。今回はとくに資料的・辞典的な側面が強い本なので検索性はかなり重要。今のOCRの性能は数年前とは比較にならないほど良くできていて、アルファベットならまったく問題はない。日本語もかなりの高精度になっている。
【作業2:しおり】ページ数が多く、また資料として使うため、章単位でしおりを入れておいた。自分ではやったこと無いのだが、目次から各章・節にリンクを入れることもできるようだ。労力に見合うと思ったらやっておくと良いかもしれない。
PDF化が終わったらあとは、PCやiPadに転送するだけだ。PCの場合はファイルを任意のフォルダにコピーするだけで良い、アドビ・リーダーがインストールされていればそのまま見ることができる。iPadの場合は、汎用のドキュメントフォルダに相当する物がないので、PDFビューアソフトによって転送先が異なる。
例えば、CloudReadersというフリーなのが申し訳ないくらい良くできているビューアの場合は、iTunesのApp画面でCloudReadersを選び、書類欄にドロップしてやれば転送される。
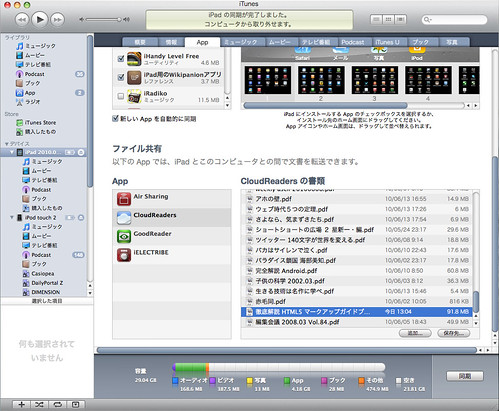
CloudReadersは、
・縦置き、横置きの両方に対応している。
・右綴じ左綴じが切り替え可能。
・画面の拡大縮小が可能。
というスキャン書類を扱うために必要な機能がすべて備わっている(今のところ)数少ないアプリケーションだ。
横置きの場合はこのように見開きで表示される(クリックで実ドットサイズの画像)。

字が小さい場合には2本指でくわっと広げて拡大表示するか、このように縦置きにして1ページ表示にすることもできる(クリックで実ドットサイズの画像)。

技術資料の場合、実際にPCに向かっていろいろ試しながら読むことが多いので、
・開いたままにしていても、本が閉じない。
・何冊でも持ち歩ける。
・前回の続きから読むことができる。
という点だけでもPDF化する価値は十分にある。初期投資は結構でかかったが、買って良かった。
とりあえず、書籍に関してはここまで。実は書籍以上に雑誌を数多く取り込んでいて、雑誌ならではのノウハウも幾つかたまってきた。そちらについても機会があればまとめてみたい。

FUJITSU ScanSnap S1500 FI-S1500
- 出版社/メーカー: 富士通
- 発売日: 2009/02/07
- メディア: Personal Computers
- 購入: 104人 クリック: 5,788回
- この商品を含むブログ (233件) を見る

プラス 断裁機 PK-513L 裁断幅A4タテ 26-106
- 出版社/メーカー: PLUS(プラス)
- 発売日: 2009/09/01
- メディア: オフィス用品
- 購入: 76人 クリック: 4,646回
- この商品を含むブログ (111件) を見る
追記:コメント欄にてご質問頂いた件
プログラムコードをグレーで強調している部分ですが、今のところ見づらくなったりOCRで認識しなくなったりといったことはありません。
たとえば、次のようなページでも

読むのには支障が無い程度にスキャンされており、下の画像のように検索にもヒットしています。
